Как работают поисковые системы Яндекс и Google. Что такое поисковая система, как она работает? Как осуществляется поиск в поисковых системах
Наиболее популярным веб сервисом современности является именно поисковая система. Тут всё объяснимо, ведь те времена, когда представители первых пользователей интернета могли наблюдать новинки в сети уже давным-давно ушли.
Информации появляется и скапливается так много, что человеку стало очень трудно найти именно ту, которая ему была бы необходима. Представьте, как бы обстоял бы поиск в интернете, если бы рядовому пользователю пришлось бы искать информацию не пойми где. Именно не пойми где, потому как ручным поиском много информации не найдёшь.
Поисковая система, что это такое?
Хорошо если пользователю уже известны сайты, на которых возможно есть нужная информация, но что делать в противном случае? Для того, чтобы облегчить жизнь человеку в поиске нужной информации в интернете и были придуманы поисковые системы или просто поисковики. Поисковая система выполняет одну очень важную функцию, без которой интернет был бы не таким как мы его привыкли видеть - это поиск информации в сети.
Поисковая система - это специальный веб узел или по-другому сайт, который предоставляет пользователям по их запросам гиперссылки на страницы, сайтов, отвечающие на заданный поисковой запрос.
Если быть немного точнее, то поиск информации в интернете, осуществляющийся благодаря программно-аппаратному функциональному набору и веб интерфейсу для взаимодействия с пользователями.
Для взаимодействия человека с поисковой системой и был создан веб интерфейс, то есть видимая и понятная оболочка. Данный подход разработчиков поисковиков облегчает поиск многим людям. Как правило, именно в интернете осуществляется поиск при помощи поисковых систем, но также существуют системы поиска для FTP-серверов, отдельных видов товаров во всемирной паутине, либо новостной информации или же другие поисковые направления.
Поиск может осуществляться не только по текстовому наполнению сайтов, но и по другим типам информации, которые человек может искать: изображения, видео, звуковые файлы и т.д.
Как осуществляется поиск поисковой системой?
Сам поиск в интернете, ровно так же как просмотр веб сайтов возможен при помощи интернет обозревателя - браузера . Только после того, как пользователь задал свой запрос в строке поиска, осуществляется непосредственно и сам поиск.
Любая поисковая система содержит программную часть, на которой основан весь поисковой механизм, его называют поисковым движком - это программный комплекс и обеспечивающий возможность поиска информации. После обращению к поисковику, формирования человеком поискового запроса и ввода его в строку поиска, поисковая система генерирует страницу со списком результатов поиска, наиболее релевантные, по мнению поисковика тут располагаются выше.
Релевантность поиска - поиск наиболее отвечающих запросу пользователя материалов и расположение на них гиперссылок на странице выдачи с более точными результатами выше других. Само распределениерезультатов называется ранжированием сайтов.
Так как же поисковик подготавливает для выдачи свои материалы и как происходит поиск информации самим поисковиком? Сбору информации в сети способствует уникальный для каждой поисковой системы робот или по-другому бот, обладающий так же рядом других синонимов как краулер или паук, а саму работу системы поиска можно разделить на три этапа:
К первому этапу работы поисковой системы можно отнести сканирование сайтов в глобальной сети и сбор на свои собственные серверы копий веб страниц. Это образует огромное количество пока ещё не обработанной и не пригодной информации для поисковой выдачи.
Второй этап работы поисковика сводится к приведению в порядок полученной ранее, на первом этапе информации от сайтов. Производится такая сортировка, которая за наименьшее время будет благоприятствовать тому самому качественному поиску, которого собственно и ждут пользователи от поисковой системы. Этап называют индексацией, это значит, что страницы уже являются подготовленными к выдаче, а актуальная база будет считаться индексом.
Как раз третий этап и обуславливает поисковую выдачу, после приёма запроса от своего клиента, опираясь на ключевые или около ключевые слова, указанные в запросе. Это способствует отбору наиболее соответствующей запросу информации, и последующей её выдачи. Так как информации, очень и очень много, поисковая система выполняет ранжирование в соответствие со своими алгоритмами.
Лучшей поисковой системой считается та, которая сможет предоставить наиболее корректно отвечающий на запрос пользователя материал. Но и тут могут встречаться результаты, на которые повлияли люди, заинтересованные в продвижение своего сайта, такие сайты хоть и не всегда, но зачастую появляются в результатах поиска, но не на долго.
Хоть мировые лидеры уже во многих регионах определены, поисковые системы продолжаются развивать свой качественный, поиск. Чем качественней поиск они смогут предоставить, тем больше людей будут им пользоваться.
Как пользоваться поисковой системой?
Что такое поисковая система и как она работает уже понятно, но как ей правильно пользоваться? На большинстве сайтов всегда присутствует строка поиска, а рядом с ней находится кнопка Найти или Поиск. В поисковую строку вводится запрос, после чего нужно нажать кнопку поиска или же как это чаще бывает, нажать клавишу Enter на клавиатуре и за считанные секунды вы получаете результат запроса в виде списка.
А вот получить правильный ответ на запрос поиска, с первого раза удаётся не всегда. Для того, чтобы поиски желаемого не становились мучительными, необходимо правильно составлять поисковый запрос и следовать нижеописанным рекомендациям.
Составляем поисковый запрос правильно
Далее будут указаны советы по использованию поисковой системы. Следование некоторым хитростям и правилам при осуществлении поиска информации в поисковой системе даст возможность получить нужный результат гораздо быстрее. Следуйте данным рекомендациям:
- Грамотное написание слов обеспечивает максимальное количество совпадений с искомым информационным объектом (Хоть современный поисковые системы уже научились исправлять орфографические ошибки, но данным советом пренебрегать не стоит).
- Благодаря использованию синонимов в запросе, можно охватить более широкий поисковой диапазон.
- Иногда изменение слова в тексте запроса может принести больший результат осуществляйте переформирование запроса.
- Привносите в запрос конкретность, используйте точные вхождения фраз, которые должны определять главную суть поиска.
- Экспериментируйте с ключевыми словами. Использование ключевых слов и словосочетаний может помочь определить главную суть, и поисковая машина выдаст более релевантный результат.
Так что такое поисковая система - это ни что иное, как возможность найти интересующую информацию и обычно совершенно бесплатно ей воспользоваться, чему-то научиться, что-то понять или сделать правильный для себя вывод. Многие уже не представляют своей жизни без голосового поиска, при котором текст не приходится набирать, свой запрос нужно всего лишь произнести, а устройством ввода информации тут является микрофон. Всё это свидетельствует о постоянном развитие поисковых технологий в интернете и необходимости в них.
В последние годы сервисы от «Гугл» и «Яндекс» прочно вошли в нашу жизнь. В этой связи многие наверняка задаются вопросом, что такое поисковая система? Говоря простыми словами, это программная система, предназначенная для поиска информации в World Wide Web. Результаты его обычно представлены в виде списка, часто называемом страницами результатов поиска (SERP). Информация может представлять собой сочетание веб-страниц, изображений и других типов файлов. Некоторые поисковые системы также содержат информацию, доступную в базах данных или открытых каталогах.
В отличие от веб-каталогов, которые поддерживаются только собственными редакторами, поисковики также содержат информацию в режиме реального времени, запуская алгоритм на веб-искателе.
История возникновения
Сами по себе поисковые системы появились ранее всемирной сети - в декабре 1990 года. Первый такой сервис назывался Archie, и он искал по командам содержимое файлов FTP.
Что такое поисковая система в Интернете? До сентября 1993 года World Wide Web была полностью проиндексирована вручную. Существовал список веб-серверов, отредактированный Тимом Бернерс-Ли, который был размещен на веб-сервере CERN. По мере того, как все большее количество серверов выходили в интернет, вышеуказанный сервис не мог успевать обрабатывать такое количество информации.

Одной из первых поисковых систем, основанных на поиске в сети, была WebCrawler, которая вышла в 1994 году. В отличие от своих предшественников, она позволяла пользователям искать любое слово на любой веб-странице. Такой алгоритм с тех пор стал стандартом для всех основных поисковых систем. Это было также первое решение, широко известное публике. Также в 1994 году был запущен сервис Lycos, который впоследствии стал крупным коммерческим проектом.
Вскоре после этого появилось много поисковых машин, и их популярность значительно выросла. К ним можно отнести Magellan, Excite, Infoseek, Inktomi, Northern Light и AltaVista. Yahoo! был одним из самых популярных способов отыскания интересующих веб-страниц, но его алгоритм поиска работал в своем собственном веб-каталоге, а не в полнотекстовых копиях страниц. Искатели информации также могли просматривать каталог, а не выполнять поиск по ключевым словам.

Новый виток развития
Компания Google приняла идею продажи поисковых запросов в 1998 году, начиная с небольшой компании goto.com. Этот шаг оказал значительное влияние на бизнес SEO, который со временем стал одним из самых прибыльных занятий в Интернете.
Примерно в 2000 году поисковая система «Гугл» стала широко известна. Компания добилась лучших результатов для многих поисков с помощью инноваций под названием PageRank. Этот итерационный алгоритм оценивает веб-страницы на основе их связей с другими сайтами и страницами, исходя из предпосылки, что хорошие или желанные источники часто упоминаются другими. Google также поддерживал минималистский интерфейс для своей поисковой системы. Напротив, многие из конкурентов встроили поисковую систему в веб-портал. На самом деле «Гугл» стала настолько популярной, что появились мошеннические движки, такие как Mystery Seeker. Сегодня существует масса региональных версий этого сервиса, в частности, поисковая система Google.ru, рассчитанная на русскоязычных пользователей.

Как работают эти сервисы?
Как же происходит ранжирование и выдача результатов? Что такое поисковые системы с точки зрения алгоритма действий? Они получают информацию через веб-сканирование с сайта на сайт. Робот или «паук» проверяет стандартное имя файла robots.txt, адресованное ему, перед отправкой определенной информации для индексации. При этом основное внимание уделяется многим факторам, а именно заголовкам, содержимому страницы, JavaScript, каскадным таблицам стилей (CSS), а также стандартной разметке HTML информационного содержимого или метаданным в метатегах HTML.
Индексирование означает связывание слов и других определяемых токенов, найденных на веб-страницах, с их доменными именами и полями на основе HTML. Ассоциации создаются в общедоступной базе данных, доступной для запросов веб-поиска. Запрос от пользователя может быть одним словом. Индекс помогает найти информацию, относящуюся к запросу как можно быстрее.
Некоторые из методов индексирования и кэширования - это коммерческие секреты, тогда как веб-сканирование - это простой процесс посещения всех сайтов на систематической основе.
Между посещениями робота кэшированная версия страницы (часть или весь контент, необходимый для ее отображения), хранящийся в рабочей памяти поисковой системы, быстро отправляется запрашивающему пользователю. Если визит просрочен, поисковик может просто действовать как веб-прокси. В этом случае страница может отличаться от индексов поиска. На кэшированном источнике отображается версия, слова которой были проиндексированы, поэтому он может быть полезен в том случае, если фактическая страница была утеряна.

Высокоуровневая архитектура
Обычно пользователь вводит запрос в поисковую систему в виде нескольких ключевых слов. У индекса уже есть имена сайтов, содержащих данные ключевые слова, и они мгновенно отображаются. Реальная загрузочная нагрузка заключается в создании веб-страниц, которые являются списком результатов поиска. Каждая страница во всем списке должна быть оценена в соответствии с информацией в индексах.
В этом случае верхний элемент результата требует поиска, реконструкции и разметки фрагментов, показывающих контекст из сопоставленных ключевых слов. Это лишь часть обработки каждой веб-страницы в результатах поиска, а дальнейшие страницы (рядом с ней) требуют большей части этой последующей обработки.
Помимо простого отыскания ключевых слов, поисковые системы предлагают свои собственные GUI- или управляемые командами операторы и параметры поиска для того, чтобы уточнить результаты.
Они обеспечивают необходимые элементы управления для пользователя с помощью цикла обратной связи, путем фильтрации и взвешивания при уточнении искомых данных с учетом начальных страниц первых результатов поиска. Например, с 2007 года Google.com позволила отфильтровать полученный список по дате, нажав «Показать инструменты поиска» в крайнем левом столбце на странице исходных результатов, а затем выбрав нужный диапазон дат.

Варьирование запросов
Большинство поисковых систем поддерживают использование логических операторов AND, OR и NOT, чтобы помочь конечным пользователям уточнить запрос. Некоторые операторы предназначены для литералов, которые позволяют пользователю уточнять и расширять условия поиска. Робот ищет слова или фразы точно так же, как и введенные команды. Некоторые поисковые системы предоставляют расширенную функцию отыскания, которая позволяет пользователям определять расстояние между ключевыми словами.
Существует также основанный на концепции поиск, в котором исследование предполагает использование статистического анализа на страницах, содержащих слова или фразы, которые вы ищете. Кроме того, запросы на естественном языке позволяют пользователю вводить вопрос в том же виде, который он задал бы человеку (самый характерный пример - ask.com).
Полезность поисковой системы зависит от релевантности набора результатов, который она выдает. Это могут быть миллионы веб-страниц, которые содержат определенное слово или фразу, но некоторые из них могут быть более релевантными, популярными или авторитетными, чем другие. В большинстве поисковых систем используются методы ранжирования, чтобы обеспечить наилучшие результаты.
Каким образом поисковик решает, какие страницы являются лучшими совпадениями с запросом, и в каком порядке должны отображаться найденные источники, сильно варьируется от одного робота к другому. Эти методы также со временем меняются по мере изменения использования Интернета и развитием новых технологий.
Что такое поисковая система: разновидности
Существует два основных типа поисковой системы. Первая - система предопределенных и иерархически упорядоченных ключевых слов, которыми люди массово ее запрограммировали. Вторая - это система, которая генерирует «инвертированный индекс», анализируя найденные тексты.

Большинство поисковых систем - коммерческие сервисы, поддерживаемые доходами от рекламы, и, таким образом, некоторые из них позволяют рекламодателям иметь рейтинг в отображаемых результатах за определенную плату. Сервисы, которые не принимают деньги за ранжирование, зарабатывают деньги, запуская контекстные объявления рядом с отображенными сайтами. На сегодняшний день продвижение в поисковых системах является одним из наиболее прибыльных заработков в сети.
Какие сервисы распространены наиболее всего?
Google - самая популярная поисковая система в мире с долей рынка 80,52% по состоянию на март 2017 года.
- Google - 80,52%
- Bing - 6,92%
- Baidu - 5,94%
- Yahoo! - 5,35%
Поисковые системы России и стран Восточной Азии
В России и некоторых странах Восточной Азии Google - не самый популярный сервис. Среди российских пользователей поисковая система «Яндекс» лидирует по популярности (61,9%) по сравнению с Google (28,3%). В Китае Baidu является самым популярным сервисом. Поисковый портал Южной Кореи - Naver используется для 70% процентов онлайн-поиска в стране. Также Yahoo! в Японии и Тайвани является наиболее популярным средством для отыскания нужных данных.
Другие известные русские поисковые системы - «Мейл» и «Рамблер». С началом развития рунета они пользовались широкой популярностью, но в настоящее время сильно сдали свои позиции.
Ограничения и критерии поиска
Несмотря на то, что поисковые системы запрограммированы на ранжирование веб-сайтов на основе некоторой их популярности и релевантности, эмпирические исследования указывают на различные политические, экономические и социальные критерии отбора информации, которую они предоставляют. Эти предубеждения могут быть прямым результатом экономических (например, компании, которые рекламируют поисковую систему, могут также стать более популярными в результатах обычного поиска) и политических процессов (например, удаление результатов поиска в соответствии с местными законами). Так, Google не будет отображать некоторые неонацистские сайты во Франции и Германии, где отрицание Холокоста является незаконным.
Христианские, исламские и еврейские поисковые системы
Глобальный рост Интернета и электронных средств массовой информации в мусульманском мире за последнее десятилетие побудил исламских приверженцев на Ближнем Востоке и Азиатском субконтиненте попытаться создать собственные поисковые системы и отфильтрованные порталы, которые позволят пользователям выполнять безопасный поиск.
Такие сервисы содержат фильтры, которые дополнительно классифицируют веб-сайты как «халяль» или «харам» на основе современного экспертного толкования «Закона Ислама».
Портал ImHalal появился в сети в сентябре 2011 года, а Halalgoogling - в июле 2013 года. Они используют фильтры харам, базируясь на алгоритмах от Google и Bing.
Другие, ориентированные на религию поисковые системы - это Jewgle (еврейская версия Google), а также христианская SeekFind.org. Они фильтрует сайты, которые отрицают или унижают их веру.
Зачем маркетологу знать базовые принципы поисковой оптимизации? Все просто: органический трафик — это прекрасный источник входящего потока целевой аудитории для вашего корпоративного сайта и даже лендингов.
Встречайте серию образовательных постов на тему SEO.
Что такое поисковая система?
Поисковая система представляет собой большую базу документов (контента). Поисковые роботы обходят ресурсы и индексируют разный тип контента, именно эти сохраненные документы и ранжируют в поиске.
По факту, Яндекс — это «слепок» Рунета (еще Турция и немного англоязычных сайтов), а Google — мирового интернета.
Поисковый индекс — структура данных, содержащая информацию о документах и расположении в них ключевых слов.
По принципу работы поисковые системы схожи между собой, различия заключаются в формулах ранжирования (упорядочивание сайтов в поисковой выдаче), которые строятся на основе машинного обучения.
Ежедневно миллионы пользователей задают запросы поисковым системам.
«Реферат написать»:

«Купить»:

Но больше всего интересуются…

Как устроена поисковая система?
Чтобы предоставлять пользователям быстрые ответы, архитектуру поиска разделили на 2 части:
- базовый поиск,
- метапоиск.
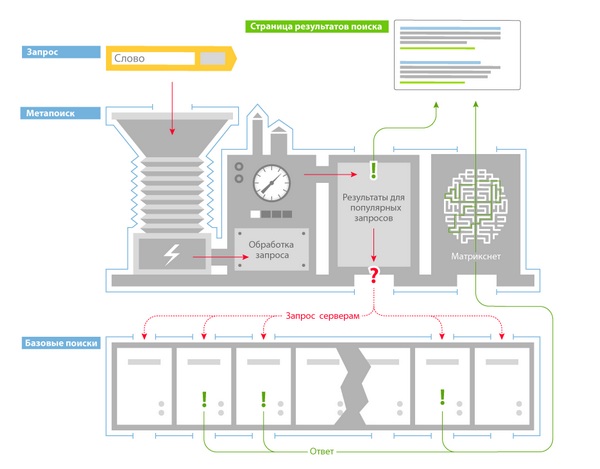
Базовый поиск
Базовый поиск — программа, которая производит поиск по своей части индекса и предоставляет все соответствующие запросу документы.
Метапоиск — программа, которая обрабатывает поисковый запрос, определяет региональность пользователя, и если запрос популярный, то выдает уже готовый вариант выдачи, а если запрос новый, то выбирает базовый поиск и отдает команду на подбор документов, далее методом машинного обучения ранжирует найденные документы и предоставляет пользователю.

Классификация поисковых запросов
Чтобы дать релевантный ответ пользователю, поисковик сначала пытается понять, что ему конкретно нужно. Происходит анализ поискового запроса и параллельный анализ пользователя.
Поисковые запросы анализируются по параметрам:
- Длина;
- четкость;
- популярность;
- конкурентность;
- синтаксис;
- география.
Тип запроса:
- навигационный;
- информационный;
- транзакционный;
- мультимедийный;
- общий;
- служебный.
После разбора и классификации запроса происходит подбор функции ранжирования.

Обозначение типов запросов является конфиденциальной информацией и предложенные варианты — это догадка специалистов по поисковому продвижению.
Если пользователь задает общий запрос, то поисковая система выдает разные типы документов. И стоит понимать, что продвигая коммерческую страницу сайта в ТОП-10 по общему запросу, вы претендуете попасть не на одно из 10 мест, а в число мест
для коммерческих страниц, которое выделяется формулой ранжирования. И следовательно, вероятность вывода в топ по таким запросам ниже.
Машинное обучение МатриксНет — алгоритм, введенный в 2009 году Яндексом, подбирающий функцию ранжирования документов по определенным запросам.

МатриксНет используется не только в поиске Яндекса, но и в научных целях. К примеру, в Европейском Центре ядерных исследований его используют для редких событий в больших объемах данных (ищут бозон Хиггса).
Первичные данные для оценки эффективности формулы ранжирования собирает отдел асессоров. Это специально обученные люди, которые оценивают выборку сайтов по экспериментальной формуле по следующим критериям.
Оценка качества сайта
Витальный — официальный сайт (Сбербанк, LPgenerator). Поисковому запросу соответствует официальный сайт, группы в социальных сетях, информация на авторитетных ресурсах.
Полезный (оценка 5) — сайт, который предоставляет расширенную информацию по запросу.
Пример — запрос: баннерная ткань.
Сайт, соответствующий оценке «полезный», должен содержать информацию:
- что такое баннерная ткань;
- технические характеристики;
- фотографии;
- виды;
- прайс-лист;
- что-то еще.
Примеры запроса в топе:

Релевантный+ (оценка 4) — это оценка означает, что страница соответствует поисковому запросу.
Релевантный- (оценка 3) — страница не точно соответствует поисковому запросу.
Допустим, по запросу «стражи галактики сеансы» выводится страница о фильме без сеансов, страница прошедшего сеанса, страница трейлера на youtube.
Нерелевантный (оценка 2) — страница не соответствует запросу.
Пример: по названию отеля выводится название другого отеля.
Чтобы продвинуть ресурс по общему или информационному запросу, нужно создавать страницу соответствующую оценке «полезный».
Для четких запросов достаточно соответствовать оценке «релевантный+».
Релевантность достигается за счет текстового и ссылочного соответствия страницы поисковым запросам.
Выводы
- Не по всем запросам можно продвинуть коммерческую целевую страницу;
- Не по всем информационным запросам можно продвинуть коммерческий сайт;
- Продвигая общий запрос, создавайте полезную страницу.
Частой причиной, почему сайт не выходит в топ, является несоответствие контента продвигаемой страницы, поисковому запросу.
Об этом поговорим в следующей статье «Чек-лист по базовой оптимизации сайта».
Здравствуйте, уважаемые читатели блога сайт. Занимаясь или, иначе говоря, поисковой оптимизацией, как на профессиональном уровне (продвигая за деньги коммерческие проекты), так и на любительском уровне (), вы обязательно столкнетесь с тем, что необходимо знать принципы работы в целом для того, чтобы успешно оптимизировать под них свой или чужой сайт.
Врага, как говорится, надо знать в лицо, хотя, конечно же, они (для рунета это Яндекс и ) для нас вовсе не враги, а скорее партнеры, ибо их доля трафика является в большинстве случаев превалирующей и основной. Есть, конечно же, исключения, но они только подтверждают данное правило.
Что такое сниппет и принципы работы поисковиков
Но тут сначала нужно будет разобраться, а что такое сниппет, для чего он нужен и почему его содержимое так важно для оптимизатора? В результатах поиска располагается сразу под ссылкой на найденный документ (текст которой берется уже писал):
В качестве сниппета используются обычно куски текста из этого документа. Идеальный вариант призван предоставить пользователю возможность составить мнение о содержимом страницы, не переходя на нее (но это, если он получился удачным, а это не всегда так).
Сниппет формируется автоматически и какие-именно фрагменты текста будут использоваться в нем решает , и, что важно, для разных запросов у одной и той же вебстраницы будут разные сниппеты.
Но есть вероятность, что именно содержимое тега Description иногда может быть использовано (особенно в Google) в качестве сниппета. Конечно же, это еще будет зависеть и от того , в выдаче которого он показывается.
Но содержимое тега Description может выводиться, например, при совпадении ключевых слов запроса и слов, употребленных вами в дескрипшине или в случае, когда алгоритм сам еще не нашел на вашем сайте фрагменты текста для всех запросов, по которым ваша страница попадает в выдачу Яндекса или Гугла.
Поэтому не ленимся и заполняем содержимое тега Description для каждой статьи. В WordPress это можно сделать, если вы используете описанный (а его использовать я вам настоятельно рекомендую).
Если вы фанат Джумлы, то можете воспользоваться этим материалом - .
Но сниппет нельзя получить из обратного индекса, т.к. там хранится информация только об использованных на странице словах и их положении в тексте. Вот именно для создания сниппетов одного и того же документа в разных поисковых выдачах (по разным запросам) наши любимые Яндекс и Гугл, кроме обратного индекса (нужного непосредственно для ведения поиска — о нем читайте ниже), сохраняют еще и прямой индекс , т.е. копию веб-страницы.
Сохраняя копию документа у себя в базе им потом довольно удобно нарезать из них нужные сниппеты, не обращаясь при этом к оригиналу.
Т.о. получается, что поисковики хранят в своей базе и прямой, и обратный индекс веб-страницы. Кстати, на формирование сниппетов можно косвенно влиять, оптимизируя текст веб-станицы таким образом, чтобы алгоритм выбирал в качестве оного именно тот фрагмент текста, который вы задумали. Но об этом поговорим уже в другой статье рубрики
Как работают поисковые системы в общих чертах
Суть оптимизации заключается в том, чтобы «помочь» алгоритмам поисковиков поднять страницы тех сайтов, которые вы продвигаете, на максимально высокую позицию в выдаче по тем или иным запросам.
Слово «помочь» в предыдущем предложении я взял в кавычки, т.к. своими оптимизаторскими действия мы не совсем помогаем, а зачастую и вовсе мешаем алгоритму сделать полностью релевантную запросу выдачу (о загадочных ).
Но это хлеб оптимизаторов, и пока алгоритмы поиска не станут совершенными, будут существовать возможности за счет внутренней и внешней оптимизации улучшить их позиции в выдаче Яндекса и Google.
Но прежде, чем переходить к изучению методов оптимизации, нужно будет хотя бы поверхностно разобраться в принципах работы поисковиков, чтобы все дальнейшие действия делать осознано и понимая зачем это нужно и как на это отреагируют те, кого мы пытаемся чуток обмануть.
Ясное дело, что понять всю логику их работы от и до у нас не получится, ибо многая информация не подлежит разглашению, но нам, на первых порах, будет достаточно и понимания основополагающих принципов. Итак, приступим.
Как же все-таки работают поисковые системы? Как ни странно, но логика работы у них всех, в принципе, одинаковая и заключается в следующем: собирается информация обо всех вебстраницах в сети, до которых они могут дотянуться, после чего эти данные хитрым образом обрабатываются для того, чтобы по ним удобно было бы вести поиск. Вот, собственно, и все, на этом статью можно считать завершенной, но все же добавим немного конкретики.
Во-первых, уточним, что документом называют то, что мы обычно называем страницей сайта. При этом он должен иметь свой уникальный адрес () и, что примечательно, хеш-ссылки не будут приводить к появлению нового документа (о том, ).
Во-вторых, стоит остановиться на алгоритмах (способах) поиска информации в собранной базе документов.
Алгоритмы прямых и обратных индексов
Очевидно, что метод простого перебора всех страниц, хранящихся в базе данных, не будет являться оптимальным. Этот метод называется алгоритмом прямого поиска и при том, что этот метод позволяет наверняка найти нужную информацию не пропустив ничего важного, он совершенно не подходит для работы с большими объемами данных, ибо поиск будет занимать слишком много времени.
Поэтому для эффективной работы с большими объемами данных был разработан алгоритм обратных (инвертированных) индексов. И, что примечательно, именно он используется всеми крупными поисковыми системами в мире. Поэтому на нем мы остановимся подробнее и рассмотрим принципы его работы.
При использовании алгоритма обратных индексов происходит преобразование документов в текстовые файлы, содержащие список всех имеющихся в них слов.
Слова в таких списках (индекс-файлах) располагаются в алфавитном порядке и рядом с каждым из них указаны в виде координат те места в вебстранице, где это слово встречается. Кроме позиции в документе для каждого слова приводятся еще и другие параметры, определяющие его значение.
Если вы вспомните, то во многих книгах (в основном технических или научных) на последних страницах приводится список слов, используемых в данной книге, с указанием номеров страниц, где они встречаются. Конечно же, этот список не включает вообще всех слов, используемых в книге, но тем не менее может служить примером построения индекс-файла с помощью инвертированных индексов.
Обращаю ваше внимание, что поисковики ищут информацию не в интернете , а в обратных индексах обработанных ими вебстраниц сети. Хотя и прямые индексы (оригинальный текст) они тоже сохраняют, т.к. он в последствии понадобится для составления сниппетов, но об этом мы уже говорили в начале этой публикации.
Алгоритм обратных индексов используется всеми системами, т.к. он позволяет ускорить процесс, но при этом будут неизбежны потери информации за счет искажений внесенных преобразованием документа в индекс-файл. Для удобства хранения файлы обратных индексов обычно хитрым способом сжимаются.
Математическая модель используемая для ранжирования
Для того, чтобы осуществлять поиск по обратным индексам, используется математическая модель, позволяющая упростить процесс обнаружения нужных вебстраниц (по введенному пользователем запросу) и процесс определения релевантности всех найденных документов этому запросу. Чем больше он соответствует данному запросу (чем он релевантнее), тем выше он должен стоять в поисковой выдаче.
Значит основная задача, выполняемая математической моделью — это поиск страниц в своей базе обратных индексов соответствующих данному запросу и их последующая сортировка в порядке убывания релевантности данному запросу.
Использование простой логической модели, когда документ будет являться найденным, если в нем встречается искомая фраза, нам не подойдет, в силу огромного количества таких вебстраниц, выдаваемых на рассмотрение пользователю.
Поисковая система должна не только предоставить список всех веб-страниц, на которых встречаются слова из запроса. Она должна предоставить этот список в такой форме, когда в самом начале будут находиться наиболее соответствующие запросу пользователя документы (осуществить сортировку по релевантности). Эта задача не тривиальна и по умолчанию не может быть выполнена идеально.
Кстати, неидеальностью любой математической модели и пользуются оптимизаторы, влияя теми или иными способами на ранжирование документов в выдаче (в пользу продвигаемого ими сайта, естественно). Матмодель, используемая всеми поисковиками, относится к классу векторных. В ней используется такое понятие, как вес документа по отношению к заданному пользователем запросу.
В базовой векторной модели вес документа по заданному запросу высчитывается исходя из двух основных параметров: частоты, с которой в нем встречается данное слово (TF — term frequency) и тем, насколько редко это слово встречается во всех других страницах коллекции (IDF — inverse document frequency).
Под коллекцией имеется в виду вся совокупность страниц, известных поисковой системе. Умножив эти два параметра друг на друга, мы получим вес документа по заданному запросу.
Естественно, что различные поисковики, кроме параметров TF и IDF, используют множество различных коэффициентов для расчета веса, но суть остается прежней: вес страницы будет тем больше, чем чаще слово из поискового запроса встречается в ней (до определенных пределов, после которых документ может быть признан спамом) и чем реже встречается это слово во всех остальных документах проиндексированных этой системой.
Оценка качества работы формулы асессорами
Таким образом получается, что формирование выдач по тем или иным запросам осуществляется полностью по формуле без участия человека. Но никакая формула не будет работать идеально, особенно на первых порах, поэтому нужно осуществлять контроль за работой математической модели.
Для этих целей используются специально обученные люди — , которые просматривают выдачу (конкретно той поисковой системы, которая их наняла) по различным запросам и оценивают качество работы текущей формулы.
Все внесенные ими замечания учитываются людьми, отвечающими за настройку матмодели. В ее формулу вносятся изменения или дополнения, в результате чего качество работы поисковика повышается. Получается, что асессоры выполняют роль такой своеобразной обратной связи между разработчиками алгоритма и его пользователями, которая необходима для улучшения качества.
Основными критериями в оценке качества работы формулы являются:
- Точность выдачи поисковой системы — процент релевантных документов (соответствующих запросу). Чем меньше не относящихся к теме запроса вебстраниц (например, дорвеев) будет присутствовать, тем лучше
- Полнота поисковой выдачи — процентное отношение соответствующих заданному запросу (релевантных) вебстраниц к общему числу релевантных документов, имеющихся во всей коллекции. Т.е. получается так, что во всей базе документов, которые известны поиску вебстраниц соответствующих заданному запросу будет больше, чем показано в поисковой выдаче. В этом случае можно говорить о неполноте выдаче. Возможно, что часть релевантных страниц попала под фильтр и была, например, принята за дорвеи или же еще какой-нибудь шлак.
- Актуальность выдачи — степень соответствия реальной вебстраницы на сайте в интернете тому, что о нем написано в результатах поиска. Например, документ может уже не существовать или быть сильно измененным, но при этом в выдаче по заданному запросу он будет присутствовать, несмотря на его физическое отсутствие по указанному адресу или же на его текущее не соответствие данному запросу. Актуальность выдачи зависит от частоты сканирования поисковыми роботами документов из своей коллекции.
Как Яндекс и Гугл собирают свою коллекцию
Несмотря на кажущуюся простоту индексации веб-страниц тут есть масса нюансов, которые нужно знать, а в последствии и использовать при оптимизации (SEO) своих или же заказных сайтов. Индексация сети (сбор коллекции) осуществляется специально предназначенной для этого программой, называемой поисковым роботом (ботом).
Робот получает первоначальный список адресов, которые он должен будет посетить, скопировать содержимое этих страниц и отдать это содержимое на дальнейшую переработку алгоритму (он преобразует их в обратные индексы).
Робот может ходить не только по заранее данному ему списку, но и переходить по ссылкам с этих страниц и индексировать находящиеся по этим ссылкам документы. Т.о. робот ведет себя точно так же, как и обычный пользователь, переходящий по ссылкам.
Поэтому получается, что с помощью робота можно проиндексировать все то, что доступно обычно пользователю, использующему браузер для серфинга (поисковики индексируют документы прямой видимости, которые может увидеть любой пользователь интернета).
Есть ряд особенностей, связанных с индексацией документов в сети (напомню, что мы уже обсуждали ).
Первой особенностью можно считать то, что кроме обратного индекса, который создается из оригинального документа скачанного из сети, поисковая система сохраняет еще и его копию, иначе говоря, поисковики хранят еще и прямой индекс. Зачем это нужно? Я уже упоминал чуть ранее, что это нужно для составления различных сниппетов в зависимости от введенного запроса.
Сколько страниц одного сайта Яндекс показывает в выдаче и индексирует
Обращаю ваше внимание на такую особенность работы Яндекса, как наличие в выдаче по заданному запросу всего лишь одного документа с каждого сайта. Такого, чтобы в выдаче присутствовали на разных позициях две страницы с одного и того же ресурса, быть не могло до недавнего времени.
Это было одно из основополагающих правил Яндекса. Если даже на одном сайте найдется сотня релевантных заданному запросу страниц, в выдаче будет присутствовать только один (самый релевантный).
Яндекс заинтересован в том, чтобы пользователь получал разнообразную информацию, а не пролистывал несколько страниц поисковой выдачи со страницами одного и того же сайта, который этому пользователю оказался не интересен по тем или иным причинам.
Однако, спешу поправиться, ибо когда дописал эту статью узнал новость, что оказывается Яндекс стал допускать отображение в выдаче второго документа с того же ресурса, в качестве исключения, если эта страница окажется «очень хороша и уместна» (иначе говоря сильно релевантна запросу).
Что примечательно, эти дополнительные результаты с того же самого сайта тоже нумеруются, следовательно, из-за этого из топа выпадут некоторые ресурсы, занимающие более низкие позиции. Вот пример новой выдачи Яндекса:

Поисковики стремятся равномерно индексировать все вебсайты, но зачастую это бывает не просто из-за совершенно разного количества страниц на них (у кого-то десять, а у кого-то десять миллионов). Как быть в этом случае?
Яндекс выходит из этого положения ограничением количества документов, которое он сможет загнать в индекс с одного сайта.
Для проектов с доменным именем второго уровня, например, сайт, максимальное количество страниц, которое может быть проиндексировано зеркалом рунета, находится в диапазоне от ста до ста пятидесяти тысяч (конкретное число зависит от отношения к данному проекту).
Для ресурсов с доменным именем третьего уровня — от десяти до тридцати тысяч страниц (документов).
Если у вас сайт с доменом второго уровня (), а вам нужно будет загнать в индекс, например, миллион вебстраниц, то единственным выходом из этой ситуации будет создание множества поддоменов ().
Поддомены для домена второго уровня могут выглядеть так: JOOMLA.сайт. Количество поддоменов для второго уровня, которое может проиндексировать Яндекс, составляет где-то чуть более 200 (иногда вроде бы и до тысячи), поэтому таким нехитрым способом вы сможете загнать в индекс зеркала рунета несколько миллионов вебстраниц.
Как Яндекс относится к сайтам в не русскоязычных доменных зонах
В связи с тем, что Яндекс до недавнего времени искал только по русскоязычной части интернета, то и индексировал он в основном русскоязычные проекты.
Поэтому, если вы создаете сайт не в доменных зонах, которые он по умолчанию относит к русскоязычным (RU, SU и UA), то ждать быстрой индексации не стоит, т.к. он, скорее всего, его найдет не ранее чем через месяц. Но уже последующая индексация будет происходить с той же частотой, что и в русскоязычных доменных зонах.
Т.е. доменная зона влияет лишь на время, которое пройдет до начала индексации, но не будет влиять в дальнейшем на ее частоту. Кстати, от чего зависит эта частота?
Логика работы поисковых систем по переиндексации страниц сводится примерно к следующему:
- найдя и проиндексировав новую страницу, робот заходит на нее на следующий день
- сравнив содержимое с тем, что было вчера, и не найдя отличий, робот придет на нее еще раз только через три дня
- если и в этот раз на ней ничего не изменится, то он придет уже через неделю и т.д.
Т.о. со временем частота прихода робота на эту страницу сравняется с частотой ее обновления или будет сопоставима с ней. Причем, время повторного захода робота может измеряться для разных сайтов как в минутах, так и в годах.
Такие вот они умные поисковые системы, составляя индивидуальный график посещения для различных страниц различных ресурсов. Можно, правда, принудить поисковики переиндексировать страничку по нашему желанию, даже если на ней ничего не изменилось, но об этом в другой статье.
Продолжим изучать принципы работы поиска в следующей статье, где мы рассмотрим проблемы, с которыми сталкиваются поисковики, рассмотрим нюансы . Ну, и многое другое, конечно же, так или иначе помогающее .
Удачи вам! До скорых встреч на страницах блога сайт
Вам может быть интересно
 Rel Nofollow и Noindex - как закрыть от индексации Яндексом и Гуглом внешние ссылки на сайте
Rel Nofollow и Noindex - как закрыть от индексации Яндексом и Гуглом внешние ссылки на сайте
 Учет морфология языка и другие проблемы решаемые поисковыми системами, а так же отличие ВЧ, СЧ и НЧ запросов
Учет морфология языка и другие проблемы решаемые поисковыми системами, а так же отличие ВЧ, СЧ и НЧ запросов
 Траст сайта - что это такое, как его измерить в XTools, что на него влияет и как увеличить авторитетности своего сайта
Траст сайта - что это такое, как его измерить в XTools, что на него влияет и как увеличить авторитетности своего сайта
 СЕО терминология, сокращения и жаргон
СЕО терминология, сокращения и жаргон
 Релевантность и ранжирование - что это такое и какие факторы влияют на положение сайтов в выдаче Яндекса и Гугла
Релевантность и ранжирование - что это такое и какие факторы влияют на положение сайтов в выдаче Яндекса и Гугла
 Какие факторы поисковой оптимизации влияют на продвижение сайта и в какой степени
Какие факторы поисковой оптимизации влияют на продвижение сайта и в какой степени
 Поисковая оптимизация текстов - оптимальная частота употребления ключевых слов и его идеальная длина
Поисковая оптимизация текстов - оптимальная частота употребления ключевых слов и его идеальная длина
 Контент для сайта - как наполнение уникальным и полезным контентом помогает в современном продвижении сайтов
Контент для сайта - как наполнение уникальным и полезным контентом помогает в современном продвижении сайтов
 Мета теги title, description и keywords мешают продвижению
Мета теги title, description и keywords мешают продвижению
 Апдейты Яндекса - какие бывают, как отслеживать ап Тиц, изменения поисковой выдачи и все другие обновления
Апдейты Яндекса - какие бывают, как отслеживать ап Тиц, изменения поисковой выдачи и все другие обновления
 Прошивка или перепрошивка телефона, смартфона и планшета Alcatel Скачать программу firmware для прошивки телефона алкатель
Прошивка или перепрошивка телефона, смартфона и планшета Alcatel Скачать программу firmware для прошивки телефона алкатель Что такое поисковая система, как она работает?
Что такое поисковая система, как она работает? Клиент Яндекс.Диска для Linux. Консольный. Резервное копирование в облако Яндекс диск.Бэкап файлов в облака Как перетащить файлы на яндекс диск
Клиент Яндекс.Диска для Linux. Консольный. Резервное копирование в облако Яндекс диск.Бэкап файлов в облака Как перетащить файлы на яндекс диск